1. kruskal.test exmaple 데이터를 엑셀로 구해보기
?kruskal.test 를 통해 example 을 확인합니다.
## Hollander & Wolfe (1973), 116.
## Mucociliary efficiency from the rate of removal of dust in normal
## subjects, subjects with obstructive airway disease, and subjects
## with asbestosis.
x <- c(2.9, 3.0, 2.5, 2.6, 3.2) # normal subjects
y <- c(3.8, 2.7, 4.0, 2.4) # with obstructive airway disease
z <- c(2.8, 3.4, 3.7, 2.2, 2.0) # with asbestosis
kruskal.test(list(x, y, z))
엑셀에 x,y,z 수치를 옮겨 적고, rank 를 구했습니다.
rank 에 동률이 없습니다.

출처 : https://en.wikipedia.org/wiki/Kruskal%E2%80%93Wallis_one-way_analysis_of_variance
위 수식에 따라 일일이 계산을 해보았습니다.
0.7714286 이 나옵니다.
kruskal.test(list(x, y, z)) 계산결과의 chi-squared 와 동일한 값입니다.
p-value 를 구해보면 0.68 이 나옵니다.
pchisq(0.77143, df = 2, lower.tail=F)
2. 기출 문제 복원
관련 자료 모음
크루스컬 월리스 공장순위데이터 문제
https://lovelydiary.tistory.com/381
5. 크루스컬 월리스 공장순위데이터 문제
각 5점 씩 총 10점
X, Y, Z 공장의 생산량 데이터와 전체 순위 데이터가 10개씩 주어짐
ADP 25회 실기 합격 후기
https://cafe.naver.com/sqlpd/36991
공장 제품무게 중앙값에 대한 가설검정에서 Kruskal-Wallis 검정 통계량을 명시하지 않아 일부 감점된것 같습니다.
[출처] 제25회 ADP 실기 시험|작성자 와이키키
https://blog.naver.com/sbp3636/222778320496
6. 무게에 따른 중위수가 3개 공장에 대해 주어지고 검정해라 (귀무, 연구가설, 데이터 있는데 df로 만들줄 알아야 한다)
(이 문제 어려운듯,,, 무게에 따른 공장별로 중위수 순서를 적어 놓고 검정해라,,, 무엇을 써야할지 모름)
문제
(후기 내용을 보고 새롭게 만든 문제입니다)
값이 아니라 중위수와 순위만 준다...
답안
귀무가설 : 모든 공장의 중앙값은 서로 같다.
대립가설 : 모든 공장의 중앙값이 전부 같은 것은 아니다.
풀이
공장이 X, Y, Z 3개이므로 분산분석을 한다. 그런데 데이터가 10개씩이므로 비모수 검정을 한다.
비모수 분산분석은 크루스칼 왈리스 검정이다.
...
공부할 자료 link
https://en.wikipedia.org/wiki/Kruskal%E2%80%93Wallis_one-way_analysis_of_variance
쿠르스칼월리스 검증
https://terms.naver.com/entry.naver?docId=512390&cid=42126&categoryId=42126
[내가 하는 통계 분석] 크루스칼 왈리스 검정(Kruskal Wallis test) in SAS
https://lunch-box.tistory.com/87
분산 분석(ANOVA)에서 정규성 가정이 만족되지 않을 때 사용하는 비모수 검정법
ANOVA와는 달리 중앙값에 관한 결과를 얻을 수 있음.
Kruskal-Wallis Test
http://www.r-tutor.com/elementary-statistics/non-parametric-methods/kruskal-wallis-test
3. rank 만 있는데 차이를 검증하는 풀이법 자료
Dr. Yury Zablotski 블로그에 여러 가지 설명과 시각화 방법 및 수작업으로 통계량 구하는 script 등 유용한 정보가 가득함.
library(tidyverse) # for data wrangling and visualization
library(broom) # for tidy test output
library(knitr) # for nice looking table
library(ggpubr) # for QQplot
library(ISLR) # for "Wage" dataset
library(conover.test) # for conover test
first_table <- Wage %>%
mutate(rank = rank(wage)) %>% # mutate means - create new column
group_by(education) %>%
summarise(rank_sum = sum(rank),
rank_mean = mean(rank),
mean_wage = mean(wage),
median_wage = median(wage),
n = n() )
# calculate the test statistics manually
first_table %>%
summarise(N = length(Wage$wage),
S_t_2 = sum(rank_sum^2/n),
S_r_2 = sum(rank(Wage$wage)^2),
C = (N*(N+1)^2 / 4),
Chisq = ((N-1)*(S_t_2 - C)) / (S_r_2 - C)) %>%
kable()
출처 : https://yury-zablotski.netlify.app/post/kruskal-wallis-test/
4. mtcars 데이터를 이용하여 aov 와 kruskal 비교
table(mtcars$cyl) 을 해보니 cyl 이 3가지 종류고 cyl 별 건수도 10건 내외라 aov 와 kruskal wallis test 비교 공부에 적합해 보입니다.
> table(mtcars$cyl)
4 6 8
11 7 14
> aov(mpg ~ cyl, data=mtcars)
Call:
aov(formula = mpg ~ cyl, data = mtcars)
Terms:
cyl Residuals
Sum of Squares 817.7130 308.3342
Deg. of Freedom 1 30
Residual standard error: 3.205902
Estimated effects may be unbalanced <== 뭔가 문제가 있다는 이야기겠지??
건수가 작아 정규성 검정 없이 비모수검정을 하면 될 듯 합니다만, shapiro.test ks.test 두 가지로 정규성 검정을 해보았습니다.
> ks.test(mtcars$mpg, "pnorm", mean= mean(mtcars$mpg), sd = sd(mtcars$mpg))
One-sample Kolmogorov-Smirnov test
data: mtcars$mpg
D = 0.1263, p-value = 0.687
alternative hypothesis: two-sided
Warning message:
In ks.test(mtcars$mpg, "pnorm", mean = mean(mtcars$mpg), sd = sd(mtcars$mpg)) :
ties should not be present for the Kolmogorov-Smirnov test
> shapiro.test(mtcars$mpg)
Shapiro-Wilk normality test
data: mtcars$mpg
W = 0.94756, p-value = 0.1229
ks.test 는 ties 가 있으면 안된다고 합니다.
0.1229 는 0.05 보다 크네요. 정규성을 가정합니다.
부연하면, 정규성을 따른다는 귀무가설을 기각하지 못합니다. 그렇다고 정규성을 가정하기에는 충분하지 않습니다.
summary(aov(mpg ~ cyl, data=mtcars))
kruskal.test(mpg ~ cyl, data=mtcars)
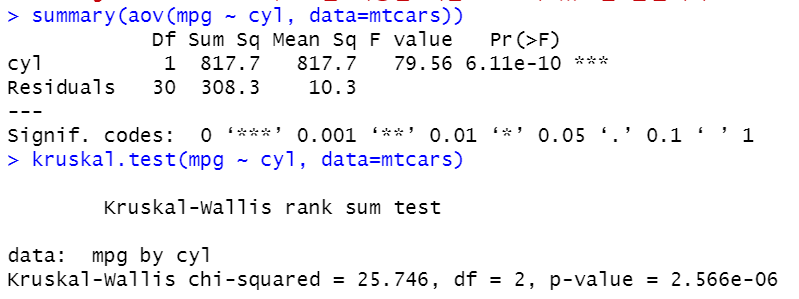
aov 와 kruskal.test는 인수를 완전히 동일하게 사용하네요.
결과 또한 둘다 차이가 없다는 귀무가설을 기각합니다.
aov 결과는 보기 불편하고, summary 해서 보는 것이 조금 나아 보입니다.
aov 결과에 Estimated effects may be unbalanced라는 메시지가 있을 뿐 에러나 강력한 경고메시지는 없습니다.
때문에 분석가가 올바른 선택을 해야만 하겠습니다.
5. kruskal.test exmaple 데이터를 이용하여 aov 와 kruskal 비교
x <- c(2.9, 3.0, 2.5, 2.6, 3.2) # normal subjects
y <- c(3.8, 2.7, 4.0, 2.4) # with obstructive airway disease
z <- c(2.8, 3.4, 3.7, 2.2, 2.0) # with asbestosis
# 데이터프레임으로 통합하기
xyz <- rbind(data.frame(v=x,g="x"),data.frame(v=y,g="y"),data.frame(v=z,g="z"))
kruskal.test(v ~ g, data = xyz)
aov(v ~ g, data = xyz)
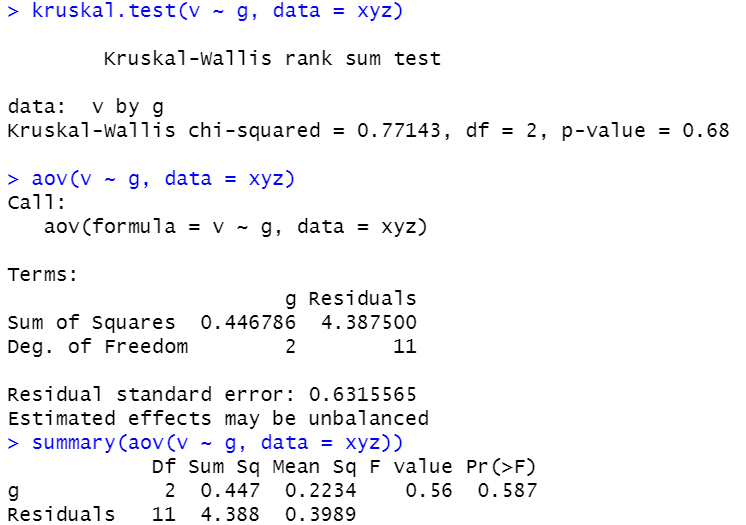
Hollander & Wolfe 데이터에 대해서는 aov 와 kruskal.test 모두 3 그룹간 차이가 없다는 귀무가설을 기각하지 못합니다.
이번에도 aov 는 Estimated effects may be unbalanced 메시지를 표시했습니다.
6. to-do
mtcars %>%
mutate(rank = rank(mpg)) %>%
select ( mpg,cyl,rank)
어떻게 rank 에 소수가 들어가는가?
anova(lm(mpg ~ cyl, data=mtcars))
* aov 와 결과가 같은데 둘의 관계는 무엇인가
참고할 link
https://rfriend.tistory.com/131
https://mansoostat.tistory.com/47
'ADP (R)' 카테고리의 다른 글
| 오늘의 ADP 준비 / 2022-07-29 금(D58) (0) | 2022.07.29 |
|---|---|
| [Adp 실기 기출 풀이] 25회 5번 공장 순위 문제 (0) | 2022.07.29 |
| [Adp 실기 기출 풀이] 25회 3-3 조건부 확률 문제 (0) | 2022.07.26 |
| 오늘의 ADP 준비 / 2022-07-26 화(D61) (0) | 2022.07.26 |
| [ADP 실기 대비 연습 문제] 조건부 확률 문제 모음 (0) | 2022.07.25 |