9월 25일 26회 시험을 준비하고 있습니다.
kukuroo3 님 캐글 (https://www.kaggle.com/code/kukuroo3/problem2-r-base?scriptVersionId=89633737) 자료입니다.
위 링크에 있는 problem2.csv 파일을 다운받아 adp20 폴더에 두고 문제를 풀어보았습니다.
1. 문제
1 데이터 전처리
각 가구의 15분간격의 전력량의 합을 구하고 해당데이터를 바탕으로 총 5개의 군집으로 군집화를 진행한 후 아래의 그림과 같은 형태로 출력하라.
군집화를 위한 데이터 구성의 이유를 설명하라
(군집 방식에 따라 Cluster컬럼의 값은 달라질수 있음)

2 히트맵
1의 데이터를 바탕으로 각 군집의 요일, 15분간격별 전력사용량의 합을 구한 후 아래와 같이 시각화 하여라
(수치는 동일하지 않을 수 있음 2-1의 데이터가 정확하게 아래와 같은 이미지로 변환 됐는지 주로 확인)
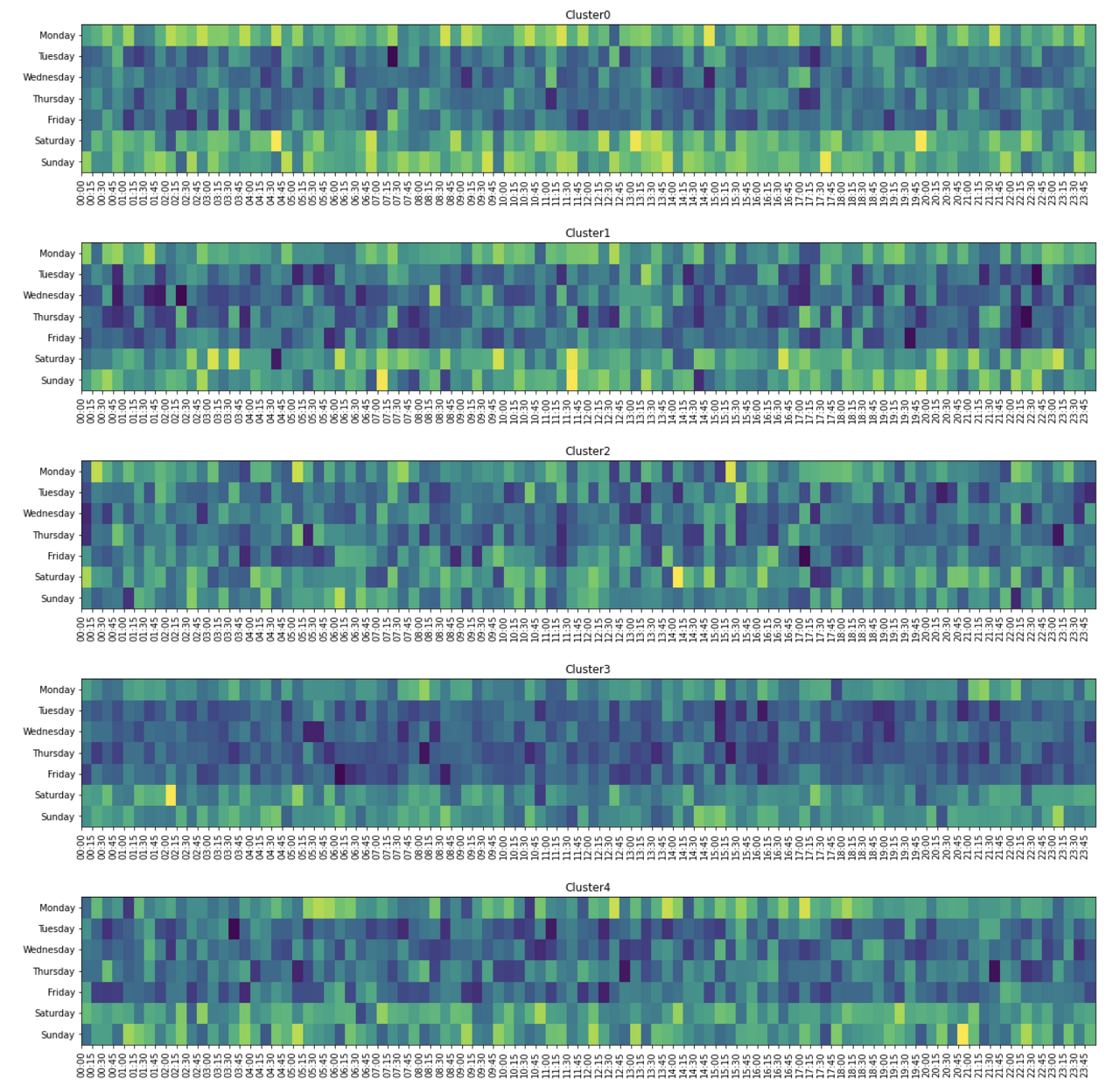
출처 https://www.kaggle.com/code/kukuroo3/problem2-r-base?scriptVersionId=89633737
2. 답안
temp <- read.csv('adp20/problem2.csv')
length(unique(temp$houseCode))
unique(temp$houseCode) #45개임
length(unique(temp$date))
library(dplyr)
library(stringr)
library(lubridate)
#1. 각 가구의 15분간격의 전력량의 합
temp %>% arrange(date) %>%
mutate(date=ymd_hms(date), min=minute(date), q= (as.numeric(min) %/% 15)*15) -> kk
minute(kk$date) <- kk$q
kk %>% select(1,2,3) %>% group_by(houseCode,date) %>%
summarize(power.consumption=sum(power.consumption)) -> sum15
#2. 해당데이터를 바탕으로 총 5개의 군집으로 군집화 진행
library(cluster)
clara(sum15,5)
NROW(sum15)
clara.sum15 <- clara(sum15,5)
str(clara.sum15)
table(clara.sum15$clustering)
# 2-1 데이터 전처리
sum15cluster <- cbind(sum15,Cluster=clara.sum15$clustering)
library(tidyverse)
library(lubridate)
library(gplots)
library(RColorBrewer)
# 2-2 히트맵
sum15cluster %>%
filter(Cluster==1) %>%
mutate(wd=wday(date,label=T,abbr=F)) %>%
mutate(hhmm=str_sub(date,12,16)) %>%
group_by(wd,hhmm) %>%
summarize(power.consumption=mean(power.consumption)) %>%
pivot_wider(names_from = hhmm,
values_from = power.consumption,
values_fill =0) %>%
ungroup() %>%
column_to_rownames(var = "wd") %>%
as.matrix() %>%
heatmap.2(col=brewer.pal(9,"Blues"),
dend="none",trace="none",key=FALSE,
margins=c(10,7),
Rowv=F,Colv=F,
cexRow=1.5,cexCol=1.2,
colRow=c("green4","maroon"),
main="Cluster1")

3. 공부 과정 log
캐글에서는 아직 파일 읽을줄을 몰라서, csv 파일을 다운받아서 로칼에 두고 R Studio 로 연습중이에요

length(unique(temp$houseCode))
unique(temp$houseCode)
-- 45개임
length(unique(temp$date))
-- 8928
15분간격 처리를 위해 date 유형에서 분 부분만 가져오자.
mssql 에서와 같이 특정 part 를 가져오는 기능이 R에는 없는 것일까?
있을 법도 한데 당장은 모르니 일단 문자열로 잘라서 쓰자
library(stringr)
?str_sub
# str_sub(string, start = 1L, end = -1L)
str_sub("2050-01-13 07:20:00",15,17)
str_sub("2050-01-13 07:20:00",15,16)
Ok
length(unique(str_sub(temp$date,15,16)))
> length(unique(str_sub(temp$date,15,16)))
[1] 12
> unique(str_sub(temp$date,15,16))
[1] "00" "10" "20" "55" "50" "35" "40" "30" "05" "45" "25"
[12] "15"
-- 정확히 5분 단위의 값들만 있는 것이다.
그럼 5분 단위로 누적인지 그 구간의 값인지 확인해보자
"house_01 2050-01-14 21" 데이터만 살펴보자
library(dplyr)
str_sub("2050-01-13 07:20:00",1,13)
temp %>% filter(houseCode=="house_01",str_sub(temp$date,1,13)== "2050-01-13 07")
-- 순서가 들쑥 날쑥
temp %>% filter(houseCode=="house_01",str_sub(temp$date,1,13)== "2050-01-13 07") %>% arrange(date)
-- 누적이 아니다.
5분 간격의 합이라고 착각했는데, 15분간격의 전력량의 합이었군...
건수가 1/3 로 줄겠네
15로 나눈 몫으로 집계를 해주면 된다.
temp %>% filter(houseCode=="house_01",str_sub(temp$date,1,13)== "2050-01-13 07") %>%
arrange(date) %>%
mutate(min=str_sub(date,15,16)) %>% #분을 추가
mutate(q= (as.numeric(min) %/% 15)+1) #분을 1,2,3,4 쿼터로 변환
temp %>% filter(houseCode=="house_01",str_sub(temp$date,1,13)== "2050-01-13 07") %>%
arrange(date) %>%
mutate(ymdhh=str_sub(date,1,13)) %>% #연월일시 lubridate 쓸수도 있는데 그냥...
mutate(min=str_sub(date,15,16)) %>% #분을 추가
mutate(q= (as.numeric(min) %/% 15)+1) %>% #분을 1,2,3,4 쿼터로 변환
group_by(houseCode,ymdhh,q) %>%
summarize(power.consumption=sum(power.consumption))
<============================= 2022-07-09
help(package="lubridate")
minute Get/set minutes component of a date-time
library(lubridate)
x <- ymd("2012-03-26")
minute(x)
lubridate::minute 함수 활용
temp %>% filter(houseCode=="house_01",str_sub(temp$date,1,13)== "2050-01-13 07") %>%
arrange(date) %>%
mutate(date=ymd_hms(date), min=minute(date), q= (as.numeric(min) %/% 15)*15) -> kk
minute(kk$date) <- kk$q
kk
> nrow(kk)
[1] 401760
> nrow(temp)
[1] 401760
> length(unique(temp$date))
[1] 8928
> length(unique(kk$date))
[1] 2976
> 8928/3
[1] 2976
> str(kk)
'data.frame': 401760 obs. of 5 variables:
$ houseCode : chr "house_42" "house_43" "house_26" "house_18" ...
$ date : POSIXct, format: "2050-01-01 00:00:00" "2050-01-01 00:00:00" "2050-01-01 00:00:00" ...
$ power.consumption: num 50.6 308.4 155.2 66.2 88 ...
$ min : int 0 0 0 0 0 0 0 0 0 0 ...
$ q : num 0 0 0 0 0 0 0 0 0 0 ...
kk %>% select(1,2,3) %>% group_by(houseCode,date) %>%
summarize(power.consumption=sum(power.consumption))
군집분석은 k-means? pam? 아무거나 선택해?
군집화를 위한 데이터 구성의 이유를 설명하라
mds pam kmeans hclust
library(cluster)
kk %>% select(1,2,3) %>% group_by(houseCode,date) %>%
summarize(power.consumption=sum(power.consumption)) -> sum15
> pam(sum15)
Error in pam(sum15) :
have 133920 observations, but not more than 65536 are allowed
<============================= 2022-07-13
1. 각 가구의 15분간격의 전력량의 합을 구하고
temp <- read.csv('adp20/problem2.csv')
length(unique(temp$houseCode))
unique(temp$houseCode) #45개임
length(unique(temp$date))
library(dplyr)
library(stringr)
library(lubridate)
temp %>% arrange(date) %>%
mutate(date=ymd_hms(date), min=minute(date), q= (as.numeric(min) %/% 15)*15) -> kk
minute(kk$date) <- kk$q
kk %>% select(1,2,3) %>% group_by(houseCode,date) %>%
summarize(power.consumption=sum(power.consumption)) -> sum15

2. 해당데이터를 바탕으로 총 5개의 군집으로 군집화를 진행
library(cluster)
clara(sum15,5)

<to-do>
군집 번호를 기존 데이터와 연결해서 표시하도록 수정
히트맵 시각화
군집분석시 clara 선택 이유 명시 또는 다른 알고리즘 활용 검토
<============================= 2022-08-08
heatmap.2 시각화 이후 레이블의 순서가 뒤죽박죽이라 Rowv=F,Colv=F, 옵션을 주었습니다.
15분 간격을 의도했는데 60+15=75분 간격으로 그려졌네요...버그수정이 필요합니다.
요일 레이블이 오른쪽에 있는데 왼쪽에 표시하는 방법도 연구가 필요합니다.
Cluster1 ~ Cluster5 중 Cluster1 하나만 히트맵을 표시했는데 5개를 모두 표시하는 것도 보완해야 합니다.
<============================= 2022-09-23
'ADP (R)' 카테고리의 다른 글
| [R 연습 문제] tapply 코드를 purrr::map 으로 변환하기 (0) | 2022.07.20 |
|---|---|
| 오늘의 ADP 준비 / 2022-07-19 화(D68) (0) | 2022.07.19 |
| purrr 을 이용해야 진정한 R 사용자 ! (0) | 2022.07.17 |
| [ADP 실기 study log] ADP 23회 객실사용여부 (풀이중) (0) | 2022.07.15 |
| [ADP 실기 study log] ADP 23회 코로나 시계열 데이터 (0) | 2022.07.14 |