1. 문제
온,습도,조도,CO2농도에 따른 객실의 사용유무 판별
종속변수 Occupancy, 0: 비어있음 , 1: 사용중
데이터 경로 : /kaggle/input/adp-kr-p1/problem1.csv
1 - (1) 데이터 EDA 수행 후, 분석가 입장에서 의미있는 탐색
1 - (2) 결측치를 대체하는 방식 선택하고 근거제시, 대체 수행
1 - (3) 추가적으로 데이터 질을 향상시킬만한 내용 작성(구현 안하고 설명만해도 됨)
2 - (1) 데이터에 불균형이 있는지 확인, 불균형 판단 근거 작성
2 - (2) 오버샘플링 방법들 중 2개 선택하고 장단점 등 선정 이유 제시
2 - (3) 오버샘플링 수행 및 결과, 잘 되었다는 것을 판단해라
3 - (1) 속도측면, 정확도측면 모델 1개씩 선택, 선택 이유도 기술
3 - (2) 위에서 오버샘플링 한 데이터 2개, 오버샘플링 하기 전 데이터 1개에 대해 모델 2개를 적용하고 성능 보여주기
3 - (3) 위 예측결과 사용해서 오버샘플링이 미친 영향에 대해 작성하라
출처 : https://www.kaggle.com/code/kukuroo3/problem-r-base?scriptVersionId=87642636
2. 답안
1 - (1) 데이터 EDA 수행 후, 분석가 입장에서 의미있는 탐색
library(randomForest)
library(recipes)
library(caret)
library(dplyr)
library(smotefamily)
temp <- read.csv("adp23/problem1.csv")
summary(temp)
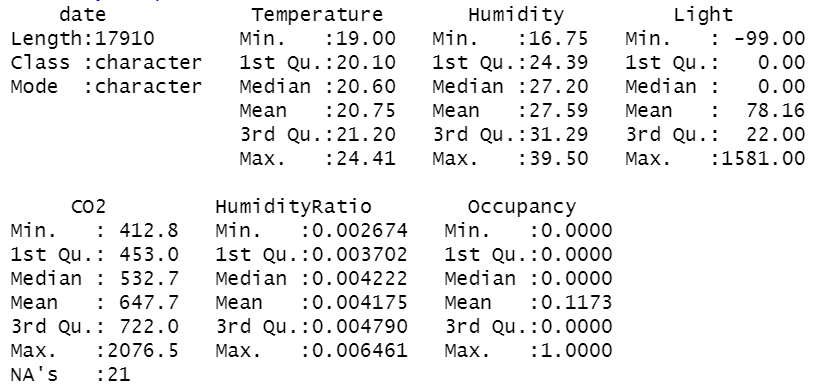
CO2 에는 결측치 21건이 존재하고 Light 에는 음수가 존재함
nrow(temp[temp$Light <0,])
unique(temp[temp$Light <0,4])

음수인 값은 50개이며 그 그값은 모두 -99 임
데이터 탐색하고 탐색 결과 제시
- 범주형 변수 그래프
- 연속형 변수 그래프
- 종속변수(여부)를 기준으로 그래프
- 조도(light) 그래프에 이상치로 보이는 데이터 존재.
추가 상세 분석이 필요하다는 정도로 이상치 제거는 하지 않음.
출처 : https://cafe.naver.com/sqlpd/28749
1 - (2) 결측치를 대체하는 방식 선택하고 근거제시, 대체 수행
샘플수가 충분히 많으니 삭제 후 분석하는 완전 분석법도 고려할 수 있으나, CO2 는 공기중에 반드시 존재하는 성격의 수치형 자료이므로 중위수로 대체하여 분석하는 것도 합리적으로 보인다.
(도대체 근거를 어떻게 제시하면 될까...)
결측치 탐색하고 대체 방법 및 근거 제시
- 결측치 존재 결측치 관련 사항 정리하여 작성
- 통계, 모델을 이용한 방법 및 모델을 이용한 적용(bagImpute) 설명
출처 : https://cafe.naver.com/sqlpd/28749
CO2 변수에 결측치가 있었음. CO2는 연속형 변수이고, 대부분의 값들이 평균값 근처였음. 하지만, 객실의 사용 여부에 따라 CO2에 차이가 있었음. 객실의 사용 여부(0, 1)에 따른 CO2 평균값으로 대체.
출처 : https://cafe.naver.com/sqlpd/28843
1 - (3) 추가적으로 데이터 질을 향상시킬만한 내용 작성(구현 안하고 설명만해도 됨)
...
알고 있는거 모두 써봄
- 범주형 변수가 있는 경우 encoding 필요
- 변수간 크기가 다른 경우 scaling 필요
- 변수가 많은 경우 feature engineering등
- 기타 ...
출처 : https://cafe.naver.com/sqlpd/28749
2 - (1) 데이터에 불균형이 있는지 확인, 불균형 판단 근거 작성
(객실의 사용유무가 1:1 이 아니면 불균형 아닌가요? 2:1 5:1 이상이면 큰 거 아닌가? 거기에 판단 근거가 필요합니까)
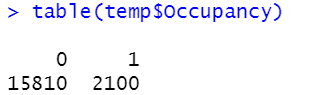
table(temp$Occupancy)
barplot(table(temp$Occupancy))

데이터 불균형 식별하고 불균형 판단 근거 작성
- 종속변수에 대한 분포표 및 막대그래프
- 12:88의 불균형 확인
출처 : https://cafe.naver.com/sqlpd/28749
2 - (2) 오버샘플링 방법들 중 2개 선택하고 장단점 등 선정 이유 제시
오버샘플링은 Random Over Sampling 과 SMOTE 2개를 선택하여 사용하겠다.
Random Over Sampling 은 기존에 존재하는 소수의 클래스를 단순 복제하여 비율을 맞춰주는 것으로 아주 간단하며 종종 효과적인 방식입니다. 그러나 똑같은 데이터가 복제되므로 오버피팅의 위험이 있습니다.
SMOTE 는 임의의 소수 클래스 데이터로부터 인근 클래스 사이에 새로운 데이터를 생성하는 것입니다.
오버샘플링 기법 설명하고 비교한 뒤 2개 기법 선정 및 근거 제시
themis 라이브러리의 step_upsampe과 step_smote 2개를 선정함
smote는 themis설명을 보고 간단히 비교하는 내용 작성
그리고 step_rose도 간단히 언급함
선정한 이유 작성하고 원데이터 포함 3개 데이터 세트 구성
- step_smote를 선정함. 간단히 사유 설명
- 원래 데이터, step_upsample 데이터, step_smote 데이터 세트 구성
출처 : https://cafe.naver.com/sqlpd/28749
2 - (3) 오버샘플링 수행 및 결과, 잘 되었다는 것을 판단해라
..
.
오버샘플링 데이터와 원데이터 사용하여 정확도 측면 모델 하나 속도 측면 모델 하나 선정
- rpart, randomforest 2 모델을 선정하여 모델링 수행
- 소요 시간을 산정하여 속도측면 rpart, 정확성을 위해 randomforest 선정
선정한 이유 작성
- 모델의 정확도를 위해서는 Randomforest를 속도를 위해서는 rpart를 선정. 주절주절 설명
오버샘플링이 미친 영향에 대해 작성
- 총 6개의 모델을 training하고 결과를 비교함.
- 오버샘플링을 수행한 모델이 accuracy, kappa가 높게 나타나 데이터 정확도를 높이는데 영향을 준다고 설명
- 불균형데이터의 경우 F1 score 또는 ROC로 성능을 평가하는 것이 정확도(accuracy)를 평가하는 것보다 모델을 보다 정확하게 평가할 수 있음
출처 : https://cafe.naver.com/sqlpd/28749
3. 참고한 자료
https://www.kaggle.com/code/moonssong/adp-220129
https://topepo.github.io/caret/subsampling-for-class-imbalances.html
https://wyatt37.tistory.com/10
https://cafe.naver.com/sqlpd/28193
https://9566.tistory.com/57?category=974088
https://cafe.naver.com/sqlpd/28843
https://cafe.naver.com/sqlpd/28758
https://cafe.naver.com/sqlpd/28749



출처 : https://9566.tistory.com/57
4. study log
2022-07-15
CO2 : 결측치가 조금(21건) 존재한다.
Occupancy : 0 과 1 두가지 값인데 0 이 1 보다 7.5 배 정도 많은 불균형
Light : 음수
Temperature Humidity : 이상치 없이 안정적인 값의 분포
Temperature boxplot 이상치 많다
Light 음수 값 분포
unique(temp[temp$Light <0,4])
-99 뿐이다. 50건
0 은 12,734 건이다. 17,910 중에 12,734 이므로 대단이 많은(71%) 비중이 0 이다.
결측치 탐색하고 대체 방법 및 근거 제시
샘플수가 충분히 많으니 그냥 지원버리자? 완전 분석법
CO2 는 공기중에 없을 수 없는 성격의 수치형 자료이므로 중위수로 대체?
데이터 불균형을 시각화하여 식별하고 불균형 판단근거 작성
오버샘플링 기법 설명하고 비교한 뒤 2개 기법 선정 및 근거제시
upSample / SMOTE
-- 일단 랜포로 분류해보기
library(randomForest)
library(recipes)
library(caret)
library(dplyr)
library(smotefamily)
temp <- read.csv("adp23/problem1.csv")
temp$Occupancy <- factor(temp$Occupancy)
r <- temp %>% recipe(Occupancy ~ .) %>%
step_mutate(Light=ifelse(Light<0,0,Light)) %>%
step_rm(date) %>%
step_impute_knn(all_predictors()) %>%
prep()
set.seed(12345)
trainIdx <- createDataPartition(temp$Occupancy,p=0.7,list=F)
train <- temp[trainIdx,]
test <- temp[-trainIdx,]
train <- bake(r,train)
test <- bake(r,test)
model <- randomForest(Occupancy ~ .,train)
pred <- predict(model, newdata=test)
cm <- confusionMatrix(pred,test$Occupancy)
cm$byClass
2022-08-16 study
caret 패키지의 upSample 설명서
## A ridiculous example...
data(oil)
table(oilType)
downSample(fattyAcids, oilType)
upSample(fattyAcids, oilType)
data(oil) 인데 느닷없이 table(oilType)... 뭐지?

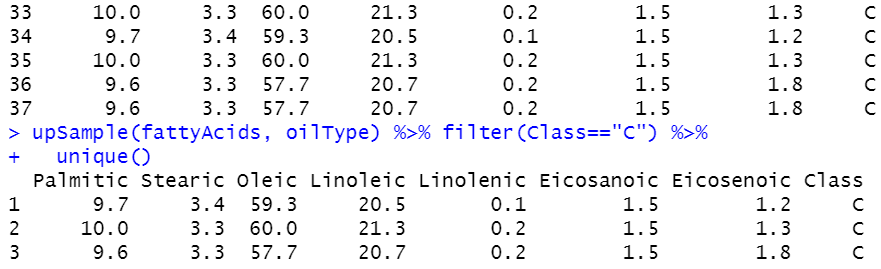
C 타입이 원본은 3개임.
upSample(fattyAcids, oilType) %>% filter(Class=="C") %>%
unique()
C 타입 데이터를 보면 많이 복제되어 있으나, unique 하개 보면 원본과 동일하게 딱 3개임.
있는 자료를 아무런 변형없이 그대로 복제한다는 사실을 확인할 수 있음
2022-08-27 study
출처 : https://www.kaggle.com/code/moonssong/adp-220129 (ADP_220129_표본추출 및 불균형 데이터 처리)
rdata <- read.csv("adp23/problem1.csv")
str(rdata) # dim 17910 7
summary(rdata) # NA 21
summary(rdata$CO2)
boxplot(rdata$CO2)
na.ratio <- sum(is.na(rdata))/nrow(rdata) # 결측치 0.1% 이하로 매우 적어 결측치 제거
na.ratio
# [1] 0.001172529
rdata <- na.omit(rdata)
sum(is.na(rdata))
# number 변수의 scale이 다르므로 min-max 표준화
normalize <- function(x){
return((x-min(x))/(max(x)-min(x)))
}
rdata$Temperature <- normalize(rdata$Temperature)
rdata$Humidity <- normalize(rdata$Humidity)
rdata$Light <- normalize(rdata$Light)
rdata$CO2 <- normalize(rdata$CO2)
rdata$HumidityRatio <- normalize(rdata$HumidityRatio)
summary(rdata)
summary(rdata$Occupancy)
class(rdata$Occupancy)
table(rdata$Occupancy)
prop.table(table(rdata$Occupancy))
barplot(prop.table(table(rdata$Occupancy))) # 데이터 불균형
# random upsampling
set.seed(504)
library(caret)
table(rdata$Occupancy)
rdata$Occupancy <- as.factor(rdata$Occupancy)
ovrdata1 <- upSample(rdata[, -c(7)], rdata$Occupancy) # 업/다운 샘플링 방법으로 샘플링
summary(ovrdata1) # Occupancy 가 Class로 변수명 자동 바뀜
ovrdata1$Occupancy <- ovrdata1$Class
ovrdata1 <- ovrdata1[, -7]
summary(ovrdata1)
prop.table(table(ovrdata1$Occupancy))
barplot(prop.table(table(ovrdata1$Occupancy)))
# SMOTE
set.seed(504)
library(smotefamily)
rdata$Occupancy <- as.numeric(rdata$Occupancy)
ovrdata2 <- SMOTE(rdata[, -c(1,7)], rdata[, 7], dup_size = 6)
table(ovrdata2$data$class)
summary(ovrdata2$data)
barplot(table(ovrdata2$data$class))
# 원본 데이터 glm 모델 적용
summary(rdata)
rdata$Occupancy <- ifelse(rdata$Occupancy == 1, "0", "1")
rdata$Occupancy <- as.numeric(rdata$Occupancy)
set.seed(504)
idx <- sample(1:nrow(rdata), nrow(rdata)*0.7, replace = F)
rtrain <- rdata[idx,]
rtest <- rdata[-idx,]
# dim(rtrain)
# dim(rtest)
# str(rtrain)
rtrain <- rtrain[,-1] #안할 시 엄청나게 시간 걸림, freeze
# str(rtrain)
rtrain.glm <- glm(Occupancy ~ ., rtrain, family = "binomial")
summary(rtrain.glm)
# str(rtest)
rtest <- rtest[,-1]
rtrain.pred <- predict(rtrain.glm, rtest[,-6], type = "response")
# head(rtrain.pred)
# head(rtrain$Occupancy)
rtrain.pred <- ifelse(rtrain.pred > 0.5, "1", "0")
head(rtrain.pred)
rtrain.pred <- as.factor(rtrain.pred)
library(caret)
confusionMatrix(rtrain.pred, as.factor(rtest[,6]), positive = "1") # Accuracy : 0.9884, kappa : 0.946
# Random Upsampling 데이터
set.seed(504)
# summary(ovrdata1)
idx <- sample(1:nrow(ovrdata1), nrow(ovrdata1)*0.7, replace = F)
ovtrain <- ovrdata1[idx,]
ovtest <- ovrdata1[-idx,]
# dim(ovtrain)
# [1] 22106 7
# dim(ovtest)
# [1] 9474 7
# str(ovtrain)
ovtrain <- ovtrain[,-1] #안할 시 freeze
# str(ovtrain)
ov.glm <- glm(Occupancy ~ ., ovtrain, family = "binomial")
summary(ov.glm)
# str(ovtest)
ovtest <- ovtest[,-1]
ov.pred <- predict(ov.glm, ovtest[,-6], type = "response")
# head(ov.pred)
ov.pred <- ifelse(ov.pred > 0.5, "1", "0")
# head(ov.pred)
confusionMatrix(as.factor(ov.pred), ovtest[,6], positive = "1") # Accuracy : 0.9878, kappa : 0.9755
# SMOTE 데이터
set.seed(504)
ovr2 <- ovrdata2$data
ovr2$Occupancy <- ovr2$class
ovr2 <- ovr2[,-6]
ovr2$Occupancy <- ifelse(ovr2$Occupancy == 1, "0", "1")
ovr2$Occupancy <- as.factor(ovr2$Occupancy)
summary(ovr2)
str(ovr2)
idx2 <- sample(1:nrow(ovr2), nrow(ovr2)*0.7, replace = F)
ovtrain2 <- ovr2[idx2,]
ovtest2 <- ovr2[-idx2,]
# dim(ovtrain2)
# [1] 21338 6
#dim(ovtest2)
# [1] 9145 6
# str(ovtrain2)
ov2.glm <- glm(Occupancy ~ ., ovtrain2, family = "binomial")
summary(ov2.glm)
# str(ovtest2)
ov2.pred <- predict(ov2.glm, ovtest2[,-6], type = "response")
# head(ov2.pred)
ov2.pred <- ifelse(ov2.pred > 0.5, "1", "0")
# head(ov2.pred)
confusionMatrix(as.factor(ov2.pred), as.factor(ovtest2[,6]), positive = "1") # Accuracy : 0.9904, kappa : 0.9807
..
'ADP (R)' 카테고리의 다른 글
| [R 연습 문제] tapply 코드를 purrr::map 으로 변환하기 (0) | 2022.07.20 |
|---|---|
| 오늘의 ADP 준비 / 2022-07-19 화(D68) (0) | 2022.07.19 |
| purrr 을 이용해야 진정한 R 사용자 ! (0) | 2022.07.17 |
| [ADP 실기 study log] ADP 23회 코로나 시계열 데이터 (0) | 2022.07.14 |
| [ADP 실기 study log] 20회 기출 2번 전력사용량 군집분석 (0) | 2022.07.09 |