27회 ADP 실기를 76.7 점 (기계학습 28.7/통계학습 48)으로 간신히 합격했습니다.
제 기억과 다른 후기에서 확인한 정보를 이용해서 기출 문제를 복원해 보았습니다.
1. 문제
3. 지하철 라인(line),월(month),상호작용이 전체이용자수(total)에 영향을 주는지 분석하시오. (단 제곱합은 Type3 를 이용)
2. 제출 답안
귀무가설 : 라인,월,상호작용에 따른 전체 이용자수의 차이는 없다.
연구가설 : 라인,월,상호작용에 따른 전체 이용자수의 차이가 있다
표본수가 30개 이상으로서 이원배치분산분석을 수행한 결과 라인에 따른 이용자수의 차이가 있고, 월에 따른 이용자수의 차이가 있고, 상호작용에 따른 이용자수의 차이가 있다.

3. 제출 답안 복기 및 해설
분산분석에서 R 의 경우 디폴트가 Type1 이라는 점은 아는데, 다른 Type으로 처리하는 방법은 모른 상태에서 접한 문제였습니다. Type3 로 처리하라는 지시사항을 보자마자 마음을 비우고 풀었습니다.
일원배치분산분석의 경우 등분산 가정을 위배하면 Welch, 정규성을 위배하면 Kruscal-Wallis 검정을 하는 것으로 알고 있었는데,시험 당시 그에 대한 고민을 하지 않았습니다.
분산분석 이후에는 쉐페 터키HSD 게임스하웰 등 여러 가지 테스트 중에서 적절한 놈을 선택하여 사후분석을 해야하는데 사후분석을 진행하지 않았습니다.
분산분석 결과 귀무가설이 채택되어서 그랬는지 시간이 부족해서였는지 기억이 나질 않습니다. 이미 Type3로 하라는 지문을 보는 순간 5점 날아갔다고 포기했고, 세세한 처리에 대해 고민하지 않았습니다.
답안은 대략 아래와 같은 코드(위 스샷에 사용된 코드임)로 작성했던 것으로 기억합니다.
library(dplyr)
subway <- read.csv("dataset/subway.csv")
nrow(subway) #72 (실제 시험은 400개 이상이었던 듯?)
subway %>%
mutate(line=as.factor(line),month=as.factor(month)) %>%
aov(total ~ line*month,data=.) %>%
summary
4. 복원하면서 느낀 점
문제를 복원해서 풀어보니 변수가 factor 인지 수치인지에 따라, 그리고 반복 측정 데이터인지 아닌지에 따라 결과들이 달라지는 것을 확인하였습니다. 그 동안 그룹 변수들이 문자형이라 신경쓰지 않고 무심코 지나갔는데, 라인번호나 월 변수가 수치형 값이라 factor 변환 필요성에 대해 배운 계기가 되었습니다.
테스트용 데이터는 호선 3가지,월12개 에 따른 데이터 36개를 이용자수만 다르게하여 2번 반복해서 총 72행으로 만들었습니다. 흐릿한 기억에 시험에서 제공된 데이터의 행수는 꽤나 많았던 것 같고 반복 측정 횟수가 여러번이지 않았을까 싶습니다.
아래 코드에서 head(36)은 반복측정을 없애는 효과가 생깁니다.
# 반복 측정이 아닌 데이터인 경우 결과가 달라지며 상호작용효과 판단 불가
subway %>%
mutate(line=as.factor(line),month=as.factor(month)) %>%
head(36)%>% # 반복측정을 일부러 제거한 경우
aov(total ~ line*month,data=.) %>% # line+month 는 된다
summary
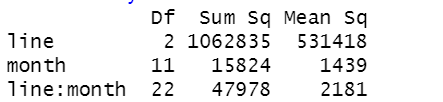
# factor 인 경우와 그렇지 않은 경우 결과가 딴판임. factor 처리를 안해주면 자유도(DF)가 1로 처리됨 주의.
subway %>%
# mutate(line=as.factor(line),month=as.factor(month)) %>%
head(36)%>% # 반복측정을 일부러 제거한 경우
aov(total ~ line*month,data=.) %>% # line+month 는 된다
summary

5. 모범 답안 연구
시험 끝나고 나중에 https://bookdown.org/ndphillips/YaRrr/type-i-type-ii-and-type-iii-anovas.html 공부해서 작성해보았습니다. Type 3 처리를 추가하여 제출하는 것이 조금 더 좋은 답안이 될 것 같습니다.
library(dplyr)
subway %>%
mutate(line=as.factor(line),month=as.factor(month)) %>%
lm(total ~ line*month,data=.) %>%
car::Anova(type = 3)
조금 더 마음에 드는 답은, https://youtu.be/3YsIUsSZ7kY 영상의 댓글에 있는 곽기영 교수님 설명을 참고하여 아래와 같이 작성하는 것입니다.
# 표본수가 30개 이상으로서 이원배치분산분석을 수행한 결과 차이가 있다.
# `Mauchly's Test for Sphericity 검정결과 pvalue 가 0.5 .05보다 작으므로 등분산 가정에 위배됨
# 보정된 자유도에 따른 결과(`Sphericity Corrections`)를 보고 판단시에도 결과는 동일함
library(rstatix)
library(dplyr)
subway %>%
mutate(line=as.factor(line),month=as.factor(month)) %>%
# mutate(id=rep(1:36, 2)) %>%
mutate(id=rep(1:2, each = 36)) %>%
anova_test(wid=id,
type=3,
dv=total
,between=month, within=line)

'ADP (R)' 카테고리의 다른 글
| [Adp 실기 기출 풀이] 27회 - Quantile 회귀 (0) | 2023.01.17 |
|---|---|
| [Adp 실기 기출 풀이] 26회 - 베이지안 회귀분석(2nd) (0) | 2023.01.14 |
| ADP 27회 실기 합격 - 공부 방법 (0) | 2023.01.05 |
| ADP 27회 실기 합격-아직도 합격예정? (0) | 2022.12.23 |
| ADP 27회 실기 합격 - 공부 기간은? (0) | 2022.12.17 |